Abstract
思维链的方式确实可以提高解决推理类的问题的性能,但是让模型生成思维链的这个过程却不是那么容易的,难点如下:
- 思维链本质是基本原理的子集,构建基本原理集需要大量数据集
- 尽管可以让大规模预训练模型通过few-shot learning的方式来生成思维链,但这样的性能不够好并且要求模型足够大
作者的提出了一个“自学推理”的过程,也就是
- 输入问题给模型
- 模型输出推理和答案
- 如果答案是错误的,那么就给出正确答案的提示,让模型再次尝试生成。
- 直到生成的答案是正确的,则让模型对这个(问题,不带提示的答案)进行微调
与微调直接预测最终答案的模型相比,STaR的性能在多个数据集上有所提高
Introduction
- 思维链工作是有效的,被明确训练为使用“草稿行”进行中间步骤的LLM可以在算术上获得完美的分布内性能,并具有强大的分布外泛化能力。这对于跨不同任务的LLM很有价值。但是两种主要的基本原理生成方法都存在严重缺陷。
- 一种是构建一个微调的基本原理数据集,人工注释员手动或用手工制作的模板自动生成。这种做法明显成本高昂,不可能为所有有趣的问题构建数据集,并且这种做法仅有在已知一般的解决方案时才有效
- 另一种是基于prompt的方式(思维链那篇论文)。这已经证明,相对于没有理由的提示(“直接”提示),可以提高数学和符号推理任务的准确性,但它们的性能通常大大低于经过微调以使用更大数据集直接预测答案的模型
Method
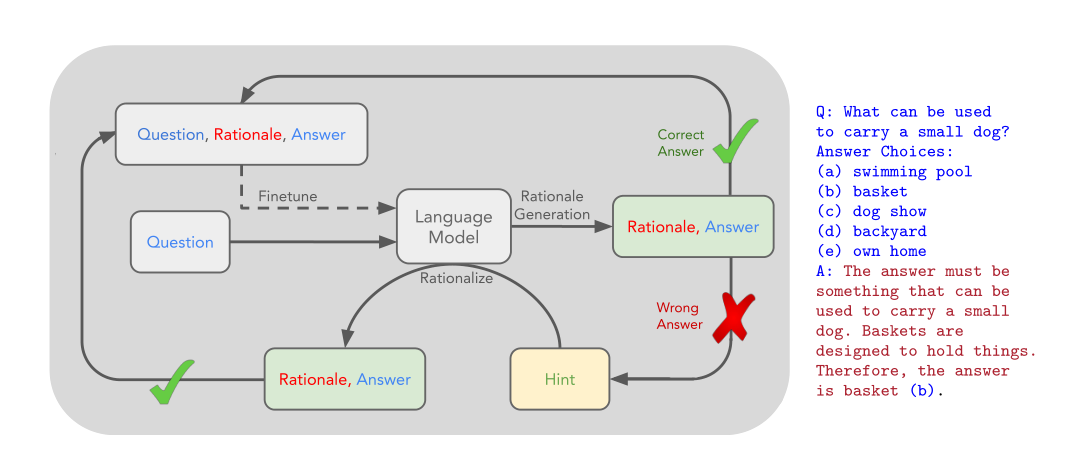
Rationale Generation Bootstrapping
- 1 原始模型为M,复制一个模型A接收x问题生成基本原理r,然后给出答案y,反复进行下去,直到x问题被接收完。
- 2 将这个过程A ->(x, r, y)进行过滤,保留所有正确答案y的过程,称这个数据集为D
- 3 在D上微调模型M,然后重新上面两个步骤
- Ps:基本可以看作是,输入x给M然后生成(r, y)
Rationalization
Ps: 基本可以看作是,输入(x, y) 给M 然后生成(r^hat, y^hat),其中y 不一定等于 y^hat
合理化的好处
- 将模型暴露于困难的问题中,否则这些问题不会出现在其微调数据集中。这可以理解为挑战模型对其不成功的问题“跳出框框思考”。
- 数据集大小的增加。
STaR算法的步骤

通俗解释上面步骤:
- 我先不看答案做题x,一通计算后得到我的答案y^以及过程步骤r^
- 然后我看着答案y做题x,一通计算后得到我的答案y^rat以及过程步骤r^rat
- 现在,我开始整理应该深入学习(值得微调的数据)的题:
- 不看答案做对的题
- 不看答案做错,但看了答案做对的题